如在云开发数据库的基础介绍中所说,云开发提供了一个 JSON 数据库,本章将介绍以下内容:
另外可参考小程序端和云函数端的数据库 API 文档
这一节我们将介绍如何在控制台中创建我们的第一个数据库集合、往集合上插入数据、以及在控制台中查看刚刚插入的数据。
打开控制台,选择 "数据库" 标签页,通过 "添加集合" 入口创建一个集合。假设我们要创建一个待办事项小程序,我们创建一个名为 todos 的集合。创建成功后,可以看到 todos 集合管理界面,界面中我们可以添加记录、查找记录、管理索引和管理权限。

控制台提供了可视化添加数据的交互界面,点击 "添加记录" 添加我们的第一条待办事项:
{
// 描述,String 类型
"description": "learn mini-program cloud service",
// 截止时间,Date 类型
"due": Date("2018-09-01"),
// 标签,Array 类型
"tags": [
"tech",
"mini-program",
"cloud"
],
// 个性化样式,Object 类型
"style": {
"color": "red"
},
// 是否已完成,Boolean 类型
"done": false
}
添加完成后可在控制台中查看到刚添加的数据。
云控制台支持上传文件导入已有的数据,可查看导入指引了解如何操作。
接下来,我们一起了解下数据库都提供了哪些数据类型。
云开发数据库提供以下几种数据类型:
下面对几个需要额外说明的字段做下补充说明。
Date 类型用于表示时间,精确到毫秒,在小程序端可用 JavaScript 内置 Date 对象创建。需要特别注意的是,在小程序端创建的时间是客户端时间,不是服务端时间,这意味着在小程序端的时间与服务端时间不一定吻合,如果需要使用服务端时间,应该用 API 中提供的 serverDate 对象来创建一个服务端当前时间的标记,当使用了 serverDate 对象的请求抵达服务端处理时,该字段会被转换成服务端当前的时间,更棒的是,我们在构造 serverDate 对象时还可通过传入一个有 offset 字段的对象来标记一个与当前服务端时间偏移 offset 毫秒的时间,这样我们就可以达到比如如下效果:指定一个字段为服务端时间往后一个小时。
那么当我们需要使用客户端时间时,存放 Date 对象和存放毫秒数是否是一样的效果呢?不是的,我们的数据库有针对日期类型的优化,建议大家使用时都用 Date 或 serverDate 构造时间对象。
GeoPoint 类型用于表示地理位置点,用经纬度唯一标记一个点,这是一个特殊的数据存储类型。注意,如果需要对类型为地理位置的字段进行查找,一定要建立地理位置索引。
具体的地理位置 API 可参考 Geo API 文档
null 相当于一个占位符,表示一个字段存在但是值为空。
数据库的权限分为小程序端和管理端,管理端包括云函数端和控制台。小程序端运行在小程序中,读写数据库受权限控制限制,管理端运行在云函数上,拥有所有读写数据库的权限。云控制台的权限同管理端,拥有所有权限。小程序端操作数据库应有严格的安全规则限制。
初期我们对操作数据库开放以下几种权限配置,每个集合可以拥有一种权限配置,权限配置的规则是作用在集合的每个记录上的。出于易用性和安全性的考虑,云开发为云数据库做了小程序深度整合,在小程序中创建的每个数据库记录都会带有该记录创建者(即小程序用户)的信息,以 _openid 字段保存用户的 openid 在每个相应用户创建的记录中。因此,权限控制也相应围绕着一个用户是否应该拥有权限操作其他用户创建的数据展开。
以下按照权限级别从宽到紧排列如下:
简而言之,管理端始终拥有读写所有数据的权限,小程序端始终不能写他人创建的数据,小程序端的记录的读写权限其实分为了 “所有人可读,只有创建者可写“、”仅创建者可读写“、”所有人可读,仅管理端可写“、”所有人不可读,仅管理端可读写“。
对一个用户来说,不同模式在小程序端和管理端的权限表现如下:
| 模式 | 小程序端
读自己创建的数据 |
小程序端
写自己创建的数据 |
小程序端
读他人创建的数据 |
小程序端
写他人创建的数据 |
管理端
读写任意数据 |
|---|---|---|---|---|---|
| 仅创建者可写,所有人可读 | √ | √ | √ | × | √ |
| 仅创建者可读写 | √ | √ | × | × | √ |
| 仅管理端可写,所有人可读 | √ | × | √ | × | √ |
| 仅管理端可读写:该数据只有管理端可读写 | × | × | × | × | √ |
在设置集合权限时应谨慎设置,防止出现越权操作。
在开始使用数据库 API 进行增删改查操作之前,需要先获取数据库的引用。以下调用获取默认环境的数据库的引用:
const db = wx.cloud.database()
如需获取其他环境的数据库引用,可以在调用时传入一个对象参数,在其中通过 env 字段指定要使用的环境。此时方法会返回一个对测试环境数据库的引用。
示例:假设有一个环境名为 test,用做测试环境,那么可以如下获取测试环境数据库:
const testDB = wx.cloud.database({
env: 'test'
})
要操作一个集合,需先获取它的引用。在获取了数据库的引用后,就可以通过数据库引用上的 collection 方法获取一个集合的引用了,比如获取待办事项清单集合:
const todos = db.collection('todos')
获取集合的引用并不会发起网络请求取拉取它的数据,我们可以通过此引用在该集合上进行增删查改的操作,除此之外,还可以通过集合上的 doc 方法来获取集合中一个指定 ID 的记录的引用。同理,记录的引用可以用于对特定记录进行更新和删除操作。
假设我们有一个待办事项的 ID 为 todo-identifiant-aleatoire,那么我们可以通过 doc 方法获取它的引用:
const todo = db.collection('todos').doc('todo-identifiant-aleatoire')
接下来,我们看看如何往集合中插入数据。
可以通过在集合对象上调用 add 方法往集合中插入一条记录。还是用待办事项清单的例子,比如我们想新增一个待办事项:
db.collection('todos').add({
// data 字段表示需新增的 JSON 数据
data: {
// _id: 'todo-identifiant-aleatoire', // 可选自定义 _id,在此处场景下用数据库自动分配的就可以了
description: "learn cloud database",
due: new Date("2018-09-01"),
tags: [
"cloud",
"database"
],
// 为待办事项添加一个地理位置(113°E,23°N)
location: new db.Geo.Point(113, 23),
done: false
},
success: function(res) {
// res 是一个对象,其中有 _id 字段标记刚创建的记录的 id
console.log(res)
}
})
当然,Promise 风格也是支持的,只要传入对象中没有 success, fail 或 complete,那么 add 方法就会返回一个 Promise:
db.collection('todos').add({
// data 字段表示需新增的 JSON 数据
data: {
description: "learn cloud database",
due: new Date("2018-09-01"),
tags: [
"cloud",
"database"
],
location: new db.Geo.Point(113, 23),
done: false
}
})
.then(res => {
console.log(res)
})
数据库的增删查改 API 都同时支持回调风格和 Promise 风格调用。
在创建成功之后,我们可以在控制台中查看到刚新增的数据。
可以在 add API 文档中查阅完整的 API 定义。
接下来,我们将学习如何使用 API 查询到刚插入的数据。
在记录和集合上都有提供 get 方法用于获取单个记录或集合中多个记录的数据。
假设我们已有一个集合 todos,其中包含以下格式记录:
[
{
_id: 'todo-identifiant-aleatoire',
_openid: 'user-open-id', // 假设用户的 openid 为 user-open-id
description: "learn cloud database",
due: Date("2018-09-01"),
progress: 20,
tags: [
"cloud",
"database"
],
style: {
color: 'white',
size: 'large'
},
location: Point(113.33, 23.33), // 113.33°E,23.33°N
done: false
},
{
_id: 'todo-identifiant-aleatoire-2',
_openid: 'user-open-id', // 假设用户的 openid 为 user-open-id
description: "write a novel",
due: Date("2018-12-25"),
progress: 50,
tags: [
"writing"
],
style: {
color: 'yellow',
size: 'normal'
},
location: Point(113.22, 23.22), // 113.22°E,23.22°N
done: false
}
// more...
]
我们先来看看如何获取一个记录的数据,假设我们已有一个 ID 为 todo-identifiant-aleatoire 的在集合 todos 上的记录,那么我们可以通过在该记录的引用调用 get 方法获取这个待办事项的数据:
db.collection('todos').doc('todo-identifiant-aleatoire').get({
success: function(res) {
// res.data 包含该记录的数据
console.log(res.data)
}
})
也可以用 Promise 风格调用:
db.collection('todos').doc('todo-identifiant-aleatoire').get().then(res => {
// res.data 包含该记录的数据
console.log(res.data)
})
我们也可以一次性获取多条记录。通过调用集合上的 where 方法可以指定查询条件,再调用 get 方法即可只返回满足指定查询条件的记录,比如获取用户的所有未完成的待办事项:
db.collection('todos').where({
_openid: 'user-open-id',
done: false
})
.get({
success: function(res) {
// res.data 是包含以上定义的两条记录的数组
console.log(res.data)
}
})
where 方法接收一个对象参数,该对象中每个字段和它的值构成一个需满足的匹配条件,各个字段间的关系是 "与" 的关系,即需同时满足这些匹配条件,在这个例子中,就是查询出 todos 集合中 _openid 等于 user-open-id 且 done 等于 false 的记录。在查询条件中我们也可以指定匹配一个嵌套字段的值,比如找出自己的标为黄色的待办事项:
db.collection('todos').where({
_openid: 'user-open-id',
style: {
color: 'yellow'
}
})
.get({
success: function(res) {
console.log(res.data)
}
})
也可以用 "点表示法" 表示嵌套字段:
db.collection('todos').where({
_openid: 'user-open-id',
'style.color': 'yellow'
})
.get({
success: function(res) {
console.log(res.data)
}
})
如果要获取一个集合的数据,比如获取 todos 集合上的所有记录,可以在集合上调用 get 方法获取,但通常不建议这么使用,在小程序中我们需要尽量避免一次性获取过量的数据,只应获取必要的数据。为了防止误操作以及保护小程序体验,小程序端在获取集合数据时服务器一次默认并且最多返回 20 条记录,云函数端这个数字则是 100。开发者可以通过 limit 方法指定需要获取的记录数量,但小程序端不能超过 20 条,云函数端不能超过 100 条。
db.collection('todos').get({
success: function(res) {
// res.data 是一个包含集合中有权限访问的所有记录的数据,不超过 20 条
console.log(res.data)
}
})
也可以用 Promise 风格调用:
db.collection('todos').get().then(res => {
// res.data 是一个包含集合中有权限访问的所有记录的数据,不超过 20 条
console.log(res.data)
})
下面是在云函数端获取一个集合所有记录的例子,因为有最多一次取 100 条的限制,因此很可能一个请求无法取出所有数据,需要分批次取:
const cloud = require('wx-server-sdk')
cloud.init()
const db = cloud.database()
const MAX_LIMIT = 100
exports.main = async (event, context) => {
// 先取出集合记录总数
const countResult = await db.collection('todos').count()
const total = countResult.total
// 计算需分几次取
const batchTimes = Math.ceil(total / 100)
// 承载所有读操作的 promise 的数组
const tasks = []
for (let i = 0; i < batchTimes; i++) {
const promise = db.collection('todos').skip(i * MAX_LIMIT).limit(MAX_LIMIT).get()
tasks.push(promise)
}
// 等待所有
return (await Promise.all(tasks)).reduce((acc, cur) => {
return {
data: acc.data.concat(cur.data),
errMsg: acc.errMsg,
}
})
}
接下来,我们将学习如何使用进阶的查询条件来完成简单或复杂的查询。
使用数据库 API 提供的 where 方法我们可以构造复杂的查询条件完成复杂的查询任务。
假设我们需要查询进度大于 30% 的待办事项,那么传入对象表示全等匹配的方式就无法满足了,这时就需要用到查询指令。数据库 API 提供了大于、小于等多种查询指令,这些指令都暴露在 db.command 对象上。比如查询进度大于 30% 的待办事项:
const _ = db.command
db.collection('todos').where({
// gt 方法用于指定一个 "大于" 条件,此处 _.gt(30) 是一个 "大于 30" 的条件
progress: _.gt(30)
})
.get({
success: function(res) {
console.log(res.data)
}
})
API 提供了以下查询指令:
| 查询指令 | 说明 |
|---|---|
| eq | 等于 |
| neq | 不等于 |
| lt | 小于 |
| lte | 小于或等于 |
| gt | 大于 |
| gte | 大于或等于 |
| in | 字段值在给定数组中 |
| nin | 字段值不在给定数组中 |
具体的查询指令 API 文档可参考数据库 API 文档。
除了指定一个字段满足一个条件之外,我们还可以通过指定一个字段需同时满足多个条件,比如用 and 逻辑指令查询进度在 30% 和 70% 之间的待办事项:
const _ = db.command
db.collection('todos').where({
// and 方法用于指定一个 "与" 条件,此处表示需同时满足 _.gt(30) 和 _.lt(70) 两个条件
progress: _.gt(30).and(_.lt(70))
})
.get({
success: function(res) {
console.log(res.data)
}
})
既然有 and,当然也有 or 了,比如查询进度为 0 或 100 的待办事项:
const _ = db.command
db.collection('todos').where({
// or 方法用于指定一个 "或" 条件,此处表示需满足 _.eq(0) 或 _.eq(100)
progress: _.eq(0).or(_.eq(100))
})
.get({
success: function(res) {
console.log(res.data)
}
})
如果我们需要跨字段进行 "或" 操作,可以做到吗?答案是肯定的,or 指令还可以用来接受多个(可以多于两个)查询条件,表示需满足多个查询条件中的任意一个,比如我们查询进度小于或等于 50% 或颜色为白色或黄色的待办事项:
const _ = db.command
db.collection('todos').where(_.or([
{
progress: _.lte(50)
},
{
style: {
color: _.in(['white', 'yellow'])
}
}
]))
.get({
success: function(res) {
console.log(res.data)
}
})
具体的逻辑查询指令 API 文档可参考数据库 API 文档。
接下来,我们一起学习如何更新数据。
现在我们一起看看如何使用数据库 API 完成数据更新。
更新数据主要有两个方法:
| API | 说明 |
|---|---|
| update | 局部更新一个或多个记录 |
| set | 替换更新一个记录 |
使用 update 方法可以局部更新一个记录或一个集合中的记录,局部更新意味着只有指定的字段会得到更新,其他字段不受影响。
比如我们可以用以下代码将一个待办事项置为已完成:
db.collection('todos').doc('todo-identifiant-aleatoire').update({
// data 传入需要局部更新的数据
data: {
// 表示将 done 字段置为 true
done: true
},
success: function(res) {
console.log(res.data)
}
})
除了用指定值更新字段外,数据库 API 还提供了一系列的更新指令用于执行更复杂的更新操作,更新指令可以通过 db.command 取得:
| 更新指令 | 说明 |
|---|---|
| set | 设置字段为指定值 |
| remove | 删除字段 |
| inc | 原子自增字段值 |
| mul | 原子自乘字段值 |
| push | 如字段值为数组,往数组尾部增加指定值 |
| pop | 如字段值为数组,从数组尾部删除一个元素 |
| shift | 如字段值为数组,从数组头部删除一个元素 |
| unshift | 如字段值为数组,往数组头部增加指定值 |
比如我们可以将一个待办事项的进度 +10%:
const _ = db.command
db.collection('todos').doc('todo-identifiant-aleatoire').update({
data: {
// 表示指示数据库将字段自增 10
progress: _.inc(10)
},
success: function(res) {
console.log(res.data)
}
})
用 inc 指令而不是取出值、加 10 再写进去的好处在于这个写操作是个原子操作,不会受到并发写的影响,比如同时有两名用户 A 和 B 取了同一个字段值,然后分别加上 10 和 20 再写进数据库,那么这个字段最终结果会是加了 20 而不是 30。如果使用 inc 指令则不会有这个问题。
如果字段是个数组,那么我们可以使用 push、pop、shift 和 unshift 对数组进行原子更新操作,比如给一条待办事项加多一个标签:
const _ = db.command
db.collection('todos').doc('todo-identifiant-aleatoire').update({
data: {
tags: _.push('mini-program')
},
success: function(res) {
console.log(res.data)
}
})
可能读者已经注意到我们提供了 set 指令,这个指令有什么用呢?这个指令的用处在于更新一个字段值为另一个对象。比如如下语句是更新 style.color 字段为 'blue' 而不是把 style 字段更新为 { color: 'blue' } 对象:
const _ = db.command
db.collection('todos').doc('todo-identifiant-aleatoire').update({
data: {
style: {
color: 'blue'
}
},
success: function(res) {
console.log(res.data)
}
})
如果需要将这个 style 字段更新为另一个对象,可以使用 set 指令:
const _ = db.command
db.collection('todos').doc('todo-identifiant-aleatoire').update({
data: {
style: _.set({
color: 'blue'
})
},
success: function(res) {
console.log(res.data)
}
})
如果需要更新多个数据,需在 Server 端进行操作(云函数),在 where 语句后同样的调用 update 方法即可,比如将所有未完待办事项的进度加 10%:
// 使用了 async await 语法
const cloud = require('wx-server-sdk')
const db = cloud.database()
const _ = db.command
exports.main = async (event, context) => {
try {
return await db.collection('todos').where({
done: false
})
.update({
data: {
progress: _.inc(10)
},
})
} catch(e) {
console.error(e)
}
}
更完整详细的更新指令可以参考数据库 API 文档
如果需要替换更新一条记录,可以在记录上使用 set 方法,替换更新意味着用传入的对象替换指定的记录:
const _ = db.command
db.collection('todos').doc('todo-identifiant-aleatoire').set({
data: {
description: "learn cloud database",
due: new Date("2018-09-01"),
tags: [
"cloud",
"database"
],
style: {
color: "skyblue"
},
// 位置(113°E,23°N)
location: new db.Geo.Point(113, 23),
done: false
},
success: function(res) {
console.log(res.data)
}
})
如果指定 ID 的记录不存在,则会自动创建该记录,该记录将拥有指定的 ID。
接下来,我们将一起学习如何删除记录。
我们一起看看如何使用数据库 API 完成数据删除。
对记录使用 remove 方法可以删除该条记录,比如:
db.collection('todos').doc('todo-identifiant-aleatoire').remove({
success: function(res) {
console.log(res.data)
}
})
如果需要更新多个数据,需在 Server 端进行操作(云函数)。可通过 where 语句选取多条记录执行删除,只有有权限删除的记录会被删除。比如删除所有已完成的待办事项:
// 使用了 async await 语法
const cloud = require('wx-server-sdk')
const db = cloud.database()
const _ = db.command
exports.main = async (event, context) => {
try {
return await db.collection('todos').where({
done: true
}).remove()
} catch(e) {
console.error(e)
}
}
在大多数情况下,我们希望用户只能操作自己的数据(自己的代表事项),不能操作其他人的数据(其他人的待办事项),这就需要引入权限控制了。
接下来,我们看看如何控制集合与记录的读写权限,达到保护数据的目的。
建立索引是保证数据库性能、保证小程序体验的重要手段。我们应为所有需要成为查询条件的字段建立索引。建立索引的入口在控制台中,可分别对各个集合的字段添加索引。
对需要作为查询条件筛选的字段,我们可以创建单字段索引。如果需要对嵌套字段进行索引,那么可以通过 "点表示法" 用点连接起嵌套字段的名称。比如我们需要对如下格式的记录中的 color 字段进行索引时,可以用 style.color 表示。
{
_id: '',
style: {
color: ''
}
}
在设置单字段索引时,指定排序为升序或降序并没有关系。在需要对索引字段按排序查询时,数据库能够正确的对字段排序,无论索引设置为升序还是降序。
组合索引即一个索引包含多个字段。当查询条件使用的字段包含在索引定义的所有字段或前缀字段里时,会命中索引,优化查询性能。索引前缀即组合索引的字段中定义的前 1 到多个字段,如有在 A, B, C 三个字段定义的组合索引 A, B, C,那么 A 和 A, B 都属于该索引的前缀。
组合索引具有以下特点:
1. 字段顺序决定索引效果
定义组合索引时,多个字段间的顺序不同是会有不同的索引效果的。比如对两个字段 A 和 B 进行索引,定义组合索引为 A, B 与定义组合索引为 B, A是不同的。当定义组合索引为 A, B 时,索引会先按 A 字段排序再按 B 字段排序。因此当组合索引设为 A, B 时,即使我们没有单独对字段 A 设立索引,但对字段 A 的查询可以命中 A, B 索引。需要注意的是,此时对字段 B 的查询是无法命中 A, B 索引的,因为 B 不属于索引 A, B 的前缀之一。
2. 字段排序决定排序查询是否可以命中索引
加入我们对字段 A 和 B 设置以下索引:
A: 升序
B: 降序
那么当我们查询需要对 A, B 进行排序时,可以指定排序结果为 A 升序 B 降序或 A 降序 B 升序,但不能指定为 A 升序 B 升序或 A 降序 B 降序。
创建索引时可以指定增加唯一性限制,具有唯一性限制的索引会要求被索引集合不能存在被索引字段值都相同的两个记录。即对任意具有唯一性限制的索引 I,假设其索引字段为 <F1, F2, ..., Fn>,则对集合 S 中任意的两个记录 R1 和 R2,必须满足条件 R1.F1 != R2.F1 && R1.F2 != R2.F2 && ... && R1.Fn != R2.Fn。需特别注意的是,假如记录中不存在某个字段,则对索引字段来说其值默认为 null,如果索引有唯一性限制,则不允许存在两个或以上的该字段为空 / 不存在该字段的记录。
在创建索引的时候索引属性选择 唯一 即可添加唯一性限制。
云开发控制台支持从文件导入已有的数据。目前仅支持导入 CSV、JSON 格式的文件数据。
要导入数据,需打开云开发控制台,切换到 “数据库” 标签页,并选择要导入数据的集合,点击 “导入” 按钮。

选择要导入的 CSV 或者 JSON 文件,以及冲突处理模式,点击 “导入” 按钮即可开始导入。
JSON、CSV 文件必须是 UTF-8 的编码格式,且其内容类似 MongoDB 的导出格式,例如:
JSON:
{
"_id": "xxxxxx",
"age": 45
}
{
"_id": "yyyyyy",
"age": 21
}
CSV:
_id,age
xxxxxx,45
yyyyyy,21
需要注意以下几点:
1、JSON 数据不是数组,而是类似 JSON Lines,即各个记录对象之间使用 \n 分隔,而非逗号;
2、JSON 数据每个键值对的键名首尾不能是 .,例如 ".a"、"abc.",且不能包含多个连续的 .,例如 "a..b";
3、键名不能重复,且不能有歧义,例如 {"a": 1, "a": 2} 或 {"a": {"b": 1}, "a.b": 2};
4、时间格式须为 ISODate 格式,例如 "date": { "$date" : "2018-08-31T17:30:00.882Z" };
5、当使用 Insert 冲突处理模式时,同一文件不能存在重复的 _id 字段,或与数据库已有记录相同的 _id 字段;
6、CSV 格式的数据默认以第一行作为导入后的所有键名,余下的每一行则是与首行键名一一对应的键值记录。
目前提供了 Insert、Upsert 两种冲突处理模式。Insert 模式会在导入时总是插入新记录,Upsert 则会判断有无该条记录,如果有则更新记录,否则就插入一条新记录。
导入完成后,可以在提示信息中看到本次导入记录的情况。

云开发控制台支持导出集合已有的数据。目前仅支持导出 CSV、JSON 格式的文件数据。
要导出数据,需打开云开发控制台,切换到 “数据库” 标签页,并选择要导出数据的集合,点击 “导出” 链接。

选择要导出的格式、保存的位置,以及字段,点击 “导出” 按钮即可开始导出的过程。
当选择导出格式为 JSON 时,若不填写字段项,则默认导出所有数据。
当选择导出格式为 CSV 时,则字段为必填项。字段之间使用英文逗号隔开,例如:
_id,name,age,gender从开发者工具 1.02.202002282 版本开始,云开发提供了数据库回档功能。系统会自动开启数据库备份,并于每日凌晨自动进行一次数据备份,最长保存 7 天的备份数据。如有需要,开发者可在云控制台上通过新建回档任务将集合回档(还原)至指定时间点。
回档期间,数据库的数据访问不受影响。回档完成后,开发者可在集合列表中看到原有数据库集合和回档后的集合。
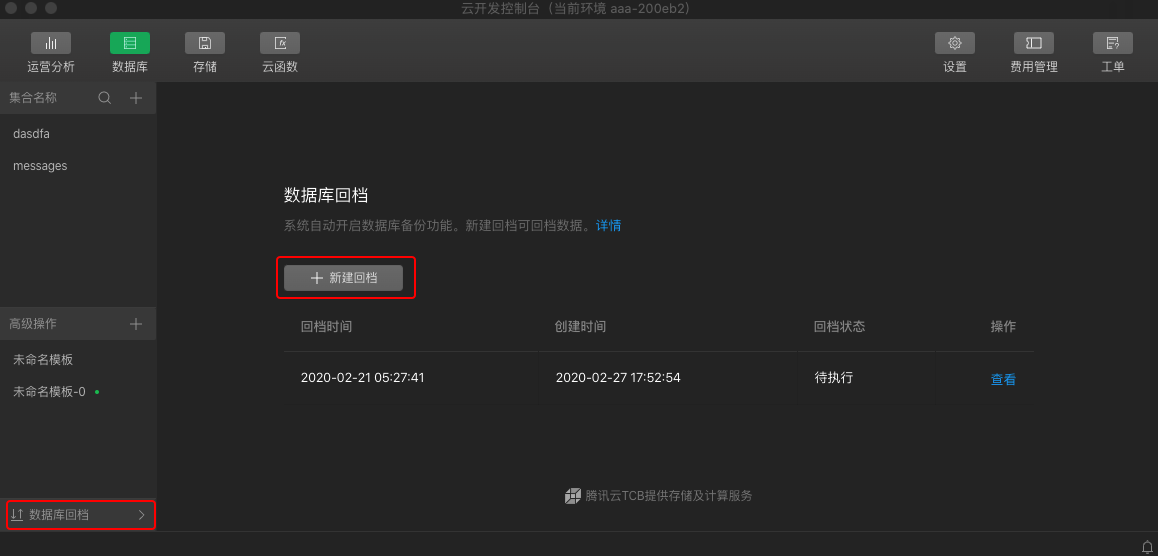
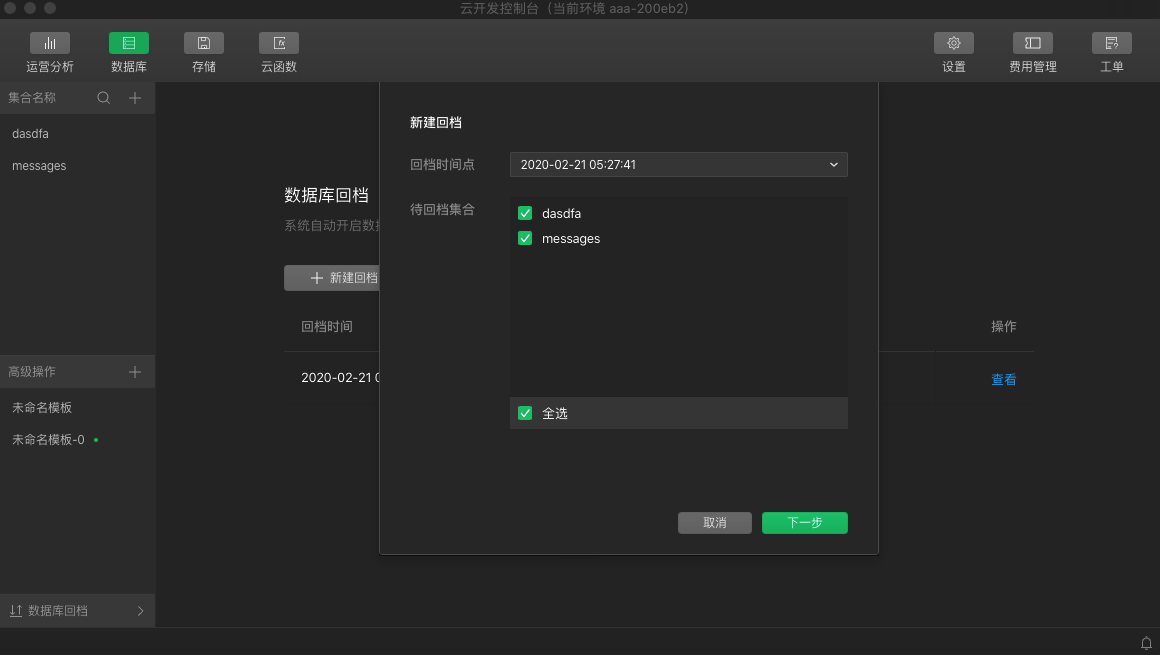
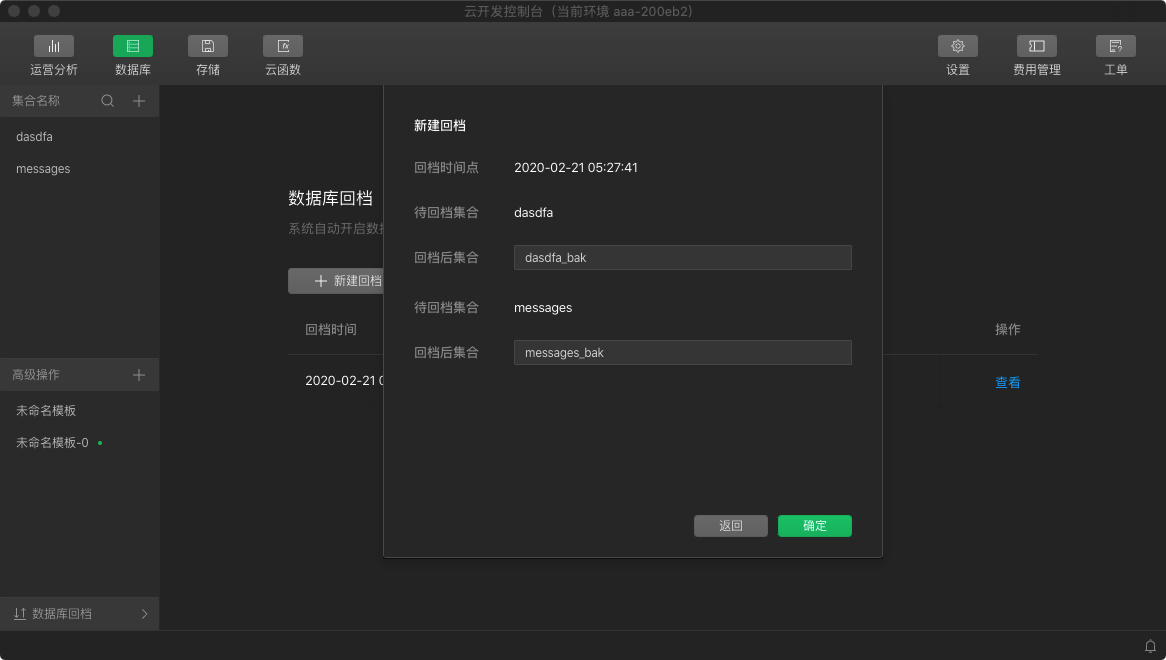
回档已完成后,如有需要,开发者可在集合列表中选择对应集合,右键重命名该集合名称。
(c) 2024 chaojicainiao.com MIT license